Before going through this tutorial take a look at the overview section to get an understanding of the structure of the tutorial.
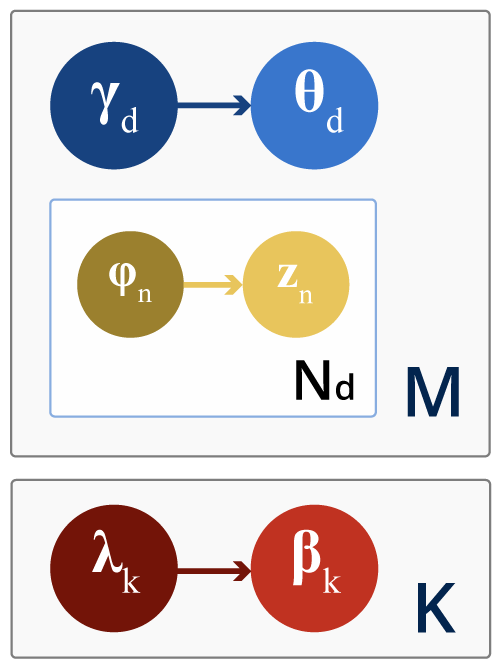
Harp LDA is a distributed variational bayes inference (VB) algorithm for LDA model which is able to model a large and continuously expanding dataset using Harp collective communication library. We demonstrate how variational bayes inference converges within Map-Collective jobs provided by Harp. We provide results of the experiments conducted on a corpus of Wikipedia Dataset.
LDA is a popular topic modeling algorithm. We follow the Mr.LDA to implement distributed variational inference LDA on Harp with it’s dynamic scheduler, allreduce and push-pull communication models.
The CVB LDA algorithm and workflow
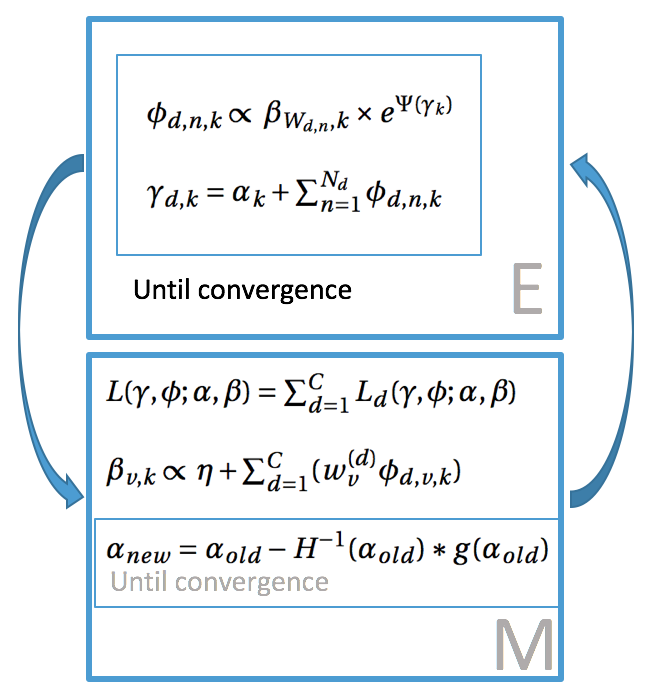
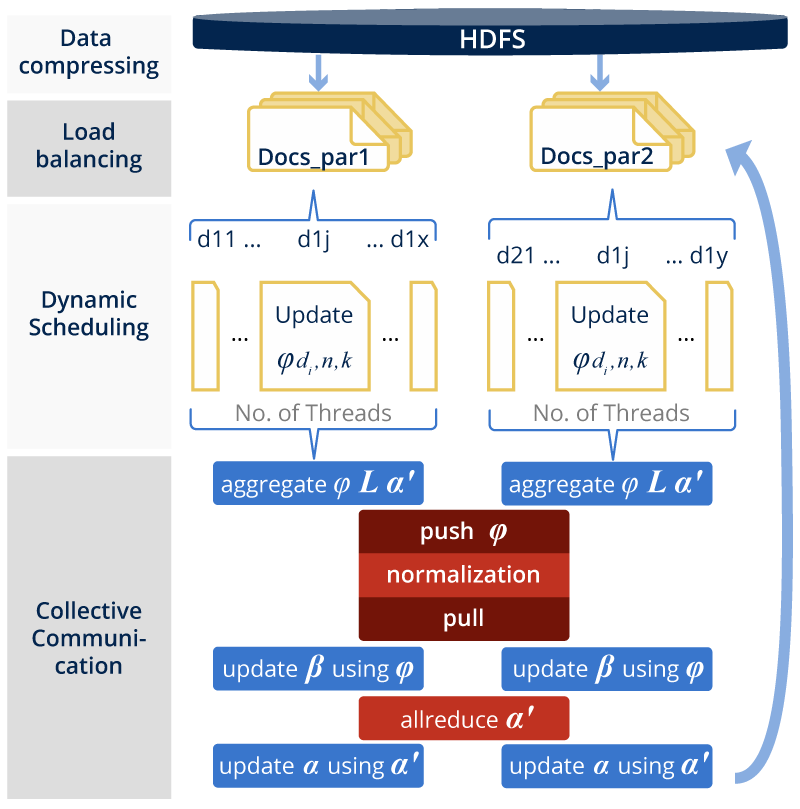
Data
The dataset used is sampled from wikipedia dataset.
Run example
Put data on hdfs
hdfs dfs -put $HARP_ROOT_DIR/datasets/tutorial/lda-cvb/sample-sparse-data/sample-sparse-metadata .
hdfs dfs -mkdir sample-sparse-data
hdfs dfs -put $HARP_ROOT_DIR/datasets/tutorial/lda-cvb/sample-sparse-data/sample-sparse-data-part-1.txt sample-sparse-data
hdfs dfs -put $HARP_ROOT_DIR/datasets/tutorial/lda-cvb/sample-sparse-data/sample-sparse-data-part-0.txt sample-sparse-data
Compile
Select the profile related to your hadoop version. For ex: hadoop-2.6.0. Supported hadoop versions are 2.6.0, 2.7.5 and 2.9.0
cd $HARP_ROOT_DIR
mvn clean package -Phadoop-2.6.0
cd $HARP_ROOT_DIR/contrib/target
cp contrib-0.1.0.jar $HADOOP_HOME
cp $HARP_ROOT_DIR/third_parity/cloud9-1.4.17.jar $HADOOP_HOME/share/hadoop/mapreduce
cd $HADOOP_HOME
Run
hadoop jar contrib-1.0.SNAPSHOT.jar edu.iu.lda.LdaMapCollective <input dir> <metafile> <output dir> <number of terms> <number of topics> <number of docs> <number of MapTasks> <number of iterations> <number of threads> <mode, 1=multithreading>
Example
hadoop jar contrib-1.0.SNAPSHOT.jar edu.iu.lda.LdaMapCollective sample-sparse-data sample-sparse-metadata sample-sparse-output 11 2 12 2 5 4 1
Please be noted:
If you are running with mode=0 (sequential version), you will need data with dense format, and the parameter “number of threads” will not be used. If you are running with mode=1, you will need data with sparse format.
Metadata is used for indicating the beginning index of documents in partitions.