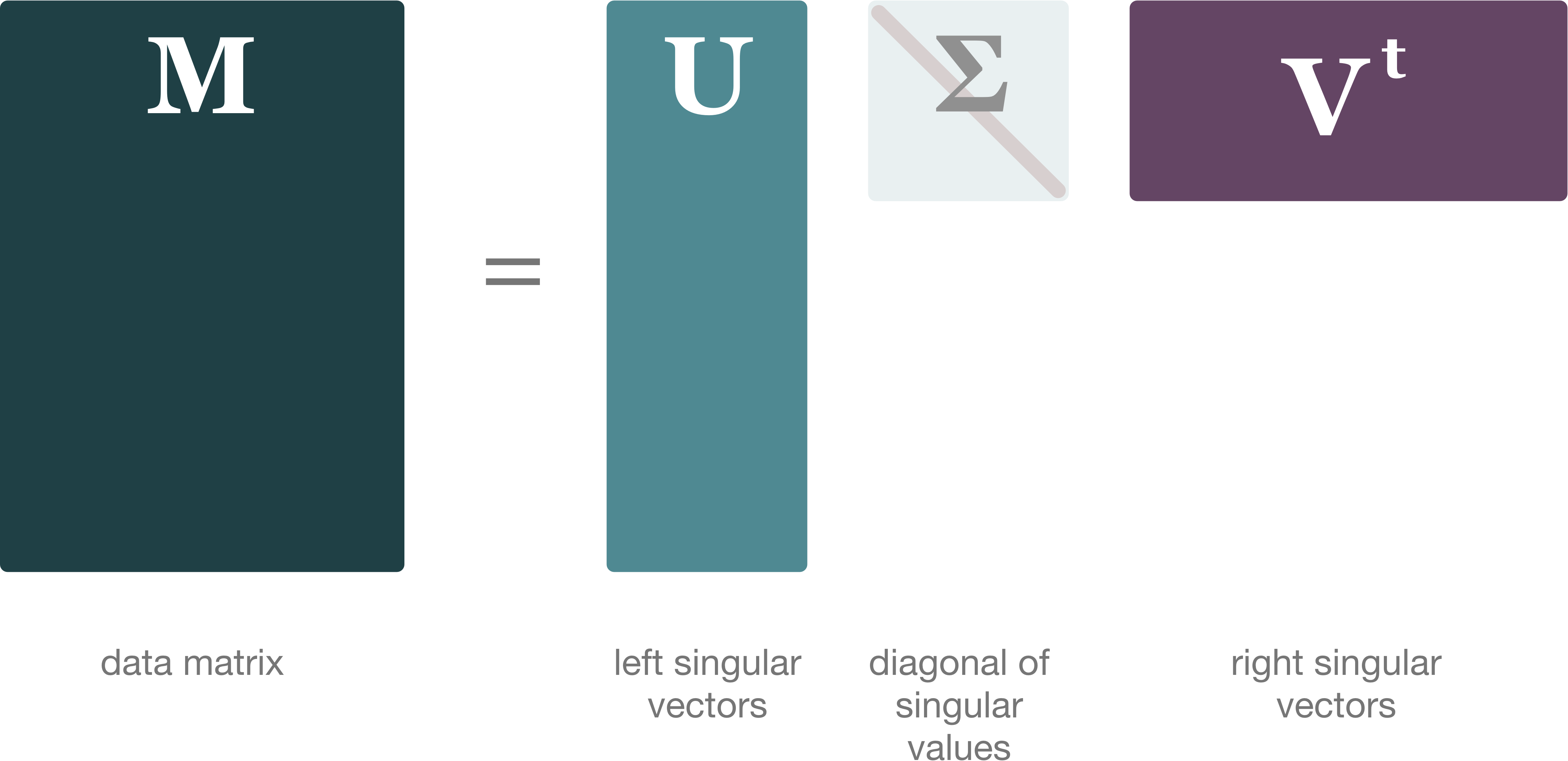
Singular Value Decomposition is a method which seeks to reduce the rank of a data matrix, thus finding the unique vectors, features, or characteristics of the data matrix at hand. This algorithm has been used in, but is not limited to signal processing, weather prediction, hotspot detection, and recommender systems.
Harp-DAAL currently supports the distributed mode for dense input datasets
More algorithmic details from Intel DAAL documentation is here.