Big Model Problems and The Limitation of Existing Tools:
Data analytics is undergoing a revolution in many scientific domains. Machine learning becomes a popular method for analytics for which it allows computers to learn from the existing data and make predictions based off it. They have been widely used in computer vision, text mining, advertising, recommender systems, network analysis and genetics. Unfortunately, analyzing such huge data usually exceeds the capability of a single or even a few machines owing to the incredible volume of data available, and thus requires algorithm parallelization at an unprecedented scale. Scaling up these algorithms is challenging because of their prohibitive computation cost, not only the need to process enormous training data in iterations, but also the requirement to synchronize big model in rounds for algorithm convergence. The problem is simply referred as “the big model problem of big data machine learning”.
Many machine learning algorithms were implemented in MapReduce. However, these implementations suffer from repeated input data loading from the distributed file systems and slow disk-based intermediate data synchronization in the shuffling phase. This motivates the design of iterative MapReduce tools which utilize memory for data caching and communication and thus drastically improve the performance of large-scale data processing. Later big data tools have expanded rapidly and form an open-source software stack. Their programming models are not limited to MapReduce and iterative MapReduce. In graph processing tools, input data are abstracted as a graph and processed in iterations, while intermediate data per iteration are expressed as messages transmitted between vertices. In parameter servers, model parameters are stored in a set of server machines and they can be retrieved asynchronously in parallel processing.
While in contemporary tools performance is improved with in-memory caching, observations show that the parallelization of these iterative applications still suffers from two issues. To simplify the programming process, many tools’ design tries to fix the parallel execution flow and developers are only required to fill the bodies of user functions. However this results in limited support of the synchronization patterns. The parallelization performance suffers from performance inefficiency due to in-proper usage of synchronization patterns. To avoid this issue, some work turn to use MPI to develop machine learning applications. However, these applications developed achieve high performance but fall into the complicated code bases since MPI only provides basic communication operations.
Harp Highlights:
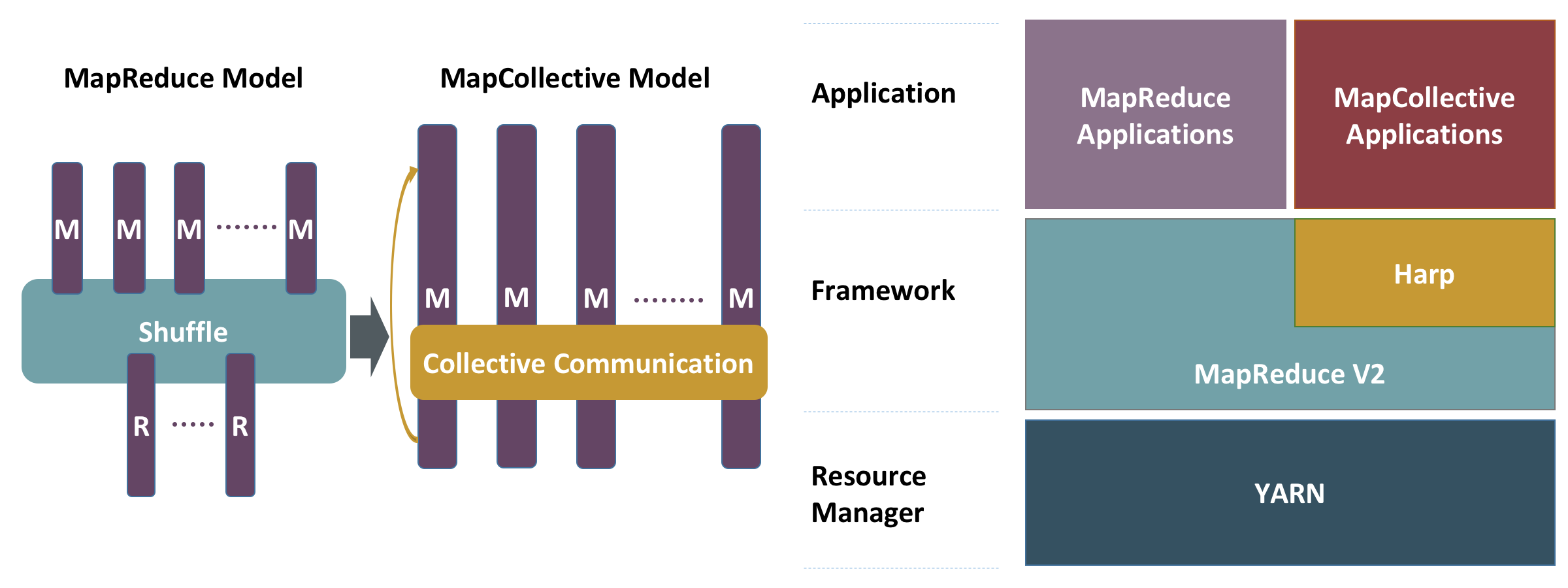
To solve the problems mentioned above, the Harp’s approach is to use collective communication techniques to improve the performance of model synchronization in parallel machine learning. Therefore a MapCollective programming model is extended from the original MapReduce programming model. Similar to the MapReduce model, the MapCollective model still read key-value pairs as inputs. However, instead of using the shuffling phase, Harp uses optimized collective communication operations for data movement and provide high-level interfaces with partitioned distributed dataset abstractions for various synchronization patterns in iterative machine learning computation. These enhancements are designed as plug-ins to Hadoop so Harp can enrich the whole big data software stack.
With the Harp framework, the project focuses on building a machine learning library with the programming interfaces provided. Our research shows parallel machine learning applications can be categorized to four types of computation models. The classification of the computation models is based on the synchronization patterns and the effectiveness of the model parameter update. These computation models are mapped to the Harp programming interfaces to simplify the programming of machine learning applications. In sum, the Harp’s contribution includes:
Harp provides a collective communication library as a Hadoop plug-in and a set of Map-Collective programming interfaces to develop iterative machine learning applications with various synchronization patterns.
Four parallel computation models are categorized to characterize the parallelization of machine learning applications. “Allreduce” and “Rotation” based Computation models can be mapped to the Harp collective communication interfaces in order to simplify the implementation of parallel machine learning applications.
A collection of machine learning algorithms are implemented, including K-means Clustering, Multiclass Logistic Regression (MLR), Support Vector Machine (SVM), Latent Dirichlet Allocation (LDA) and Matrix Factorization (MF). Our experiment results of LDA implementations reveal that the “Rotation” based computation model is faster than the “Allreduce” type computation model. Now three algorithms are built on top of model rotation: Collapsed Gibbs Sampling (CGS) for LDA, Stochastic Gradient Descent (SGD) and Cyclic Coordinate Descent (CCD) for MF. The performance results on an Intel Haswell cluster show that our solution achieves faster model convergence speed and higher scalability compared with other related work.